Production Deployment
Meshery is a powerful, extensible engineering platform for the collaborative design and operation of cloud and cloud native infrastructure. Running it in production—as a shared, always-on management plane that teams depend on—calls for deliberate planning across reliability, scalability, security, and operability.
This documentation set collects the considerations, best practices, known caveats, and hardening guidance you need to deploy and operate Meshery with confidence in a production environment. It does not replace the installation guides; rather, it builds on them with the “what to think about and why” that production demands.
Platform engineers, SREs, and operators who are standing up Meshery as a durable, multi-user service—whether self-hosted in a single cluster, spread across multiple clusters and clouds, or run out-of-cluster alongside the infrastructure it manages.
How Meshery is deployed
Meshery deploys as a set of containers that can run on a Docker host or inside a Kubernetes cluster. Any given deployment is described as either in-cluster (Meshery runs inside a cluster it also manages) or out-of-cluster (Meshery runs separately from the clusters it manages). A single Meshery Server can manage many clusters concurrently, across one or more clouds.
For an authoritative description of each component and how the pieces fit together, start with the Meshery Architecture reference. The Deployment Models & Reference Architecture page in this set translates that architecture into production topology decisions.
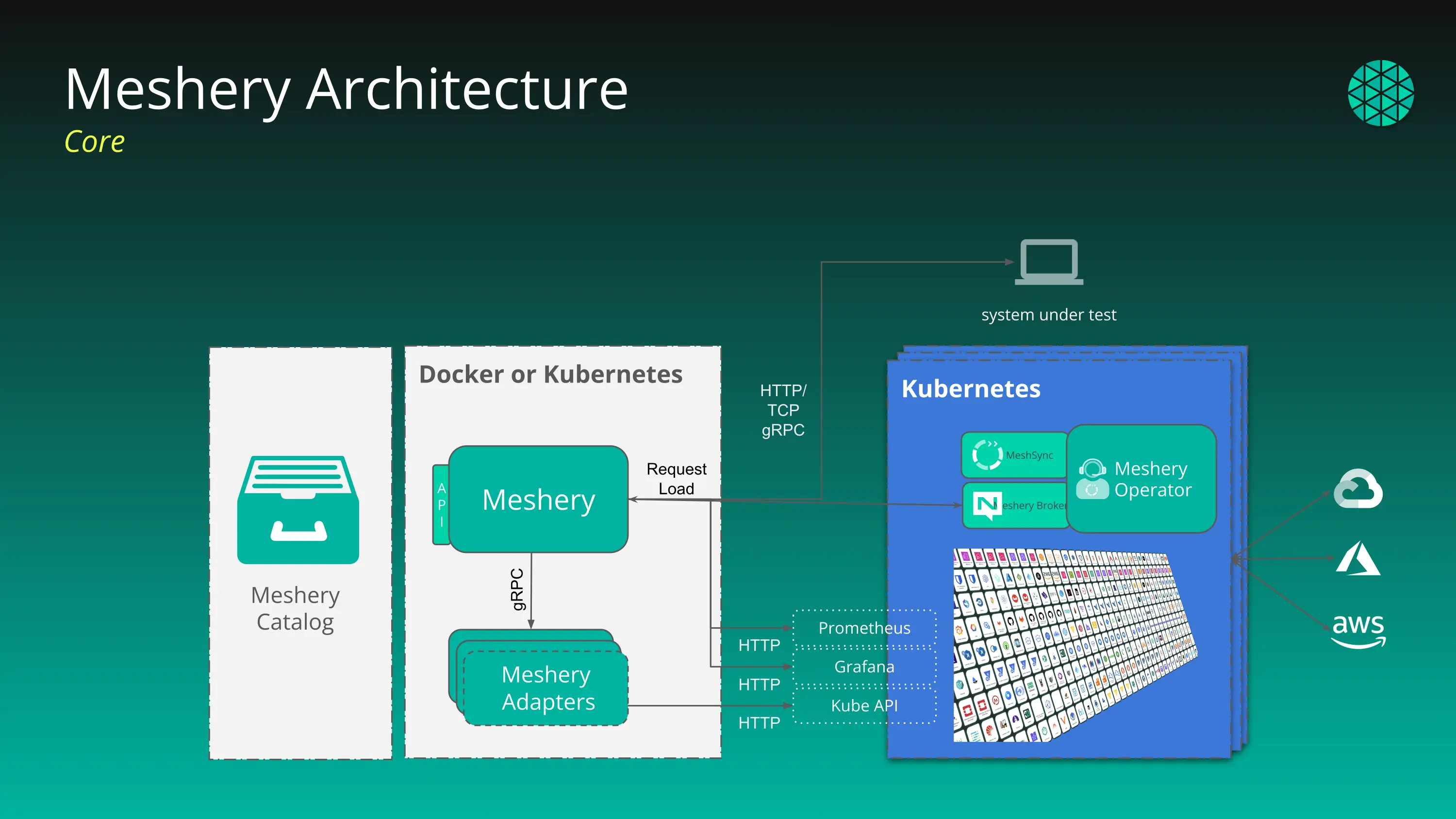
Figure: Meshery deploys inside or outside of a Kubernetes cluster and manages one or more clusters.
The production considerations, by area
This set is organized so you can read it end-to-end or jump to the area you are working on. Each page is self-contained and cross-links to the relevant reference material.
| Area | What it covers |
|---|---|
| Deployment Models & Reference Architecture | In-cluster vs. out-of-cluster, Docker vs. Kubernetes, component inventory and statefulness, and the single-cluster, multi-cluster, and multi-cloud topology patterns. |
| Infrastructure, Sizing & Performance | Resource requirements per component, capacity planning, MeshSync tiered discovery, Broker throughput, scalability levers, and known performance bounds. |
| High Availability & Resiliency | Replication, health probes, failure modes and recovery, the ephemeral database, Remote Provider persistence, and backup & disaster recovery posture. |
| Networking & Connectivity | Network port and directional-flow matrix, ingress and Emissary configuration, secure WebSocket support, CDN and edge caching of the UI, Broker exposure, egress, and network policies. |
| Security Hardening | RBAC and least privilege, pod and container security contexts, secret and kubeconfig handling, TLS, supply-chain integrity, and namespace isolation. |
| Authentication, Authorization & Identity | Why to preselect a Remote Provider over the Local Provider, OAuth callback configuration, identity providers, and keys/permissions. |
| Multi-Cluster & Multi-Cloud Operations | Managed vs. unmanaged cluster connections, one Operator per cluster, kubeconfig and context management, MeshSync modes, and cloud-specific guidance. |
| Monitoring, Observability & Health KPIs | Health endpoints, the key performance indicators of Meshery’s health, metrics, tracing, centralized logging, and alerting. |
| Operational Readiness Checklist & Known Caveats | A consolidated, actionable checklist across every dimension, plus upgrade strategy and the caveats to plan around. |
Production-readiness principles
A few principles recur throughout this set. Keep them in mind as you make deployment decisions:
- Treat the Meshery database as a cache, not a system of record. Meshery’s on-disk database is ephemeral and tied to the lifetime of its Server instance. Durable, long-term state lives with a Remote Provider. Design accordingly.
- Prefer a preselected Remote Provider in production. Pinning a Remote Provider avoids unauthenticated Local Provider sessions and lets you control which identity providers are accepted. See Authentication, Authorization & Identity.
- Right-size for discovery, not just for traffic. Meshery’s footprint is driven as much by the size and number of clusters it discovers (via MeshSync) as by user-facing API load.
- Make connectivity explicit. Know which ports flow in which direction between Meshery Server, the Broker, and each managed cluster—especially for out-of-cluster and multi-cloud topologies.
- Observe the management plane itself. Meshery exposes health endpoints and metrics; treat them as first-class signals and alert on them.
Before you begin
If you have not yet chosen an installation method, review the Installation Overview and the platform-specific guides. For Kubernetes production deployments, the Helm chart is the recommended path and is referenced throughout this set. For runtime configuration, keep the Meshery Server Environment Variables reference close at hand.
- Deployment Models & Reference Architecture - In-cluster vs. out-of-cluster, Docker vs. Kubernetes, the Meshery component inventory and its statefulness, and the topology patterns for single-cluster, multi-cluster, and multi-cloud production deployments.
- Infrastructure, Sizing & Performance - Resource requirements per Meshery component, capacity planning, MeshSync tiered discovery, Broker throughput, scalability levers, and the known performance bounds to plan around in production.
- High Availability & Resiliency - Replication, health probes, failure modes and recovery, the ephemeral database, Remote Provider persistence, and backup & disaster-recovery posture for resilient Meshery operation.
- Networking & Connectivity - Network ports and directional flows, ingress and Emissary configuration, secure WebSocket support, CDN and edge caching of the UI, Broker exposure, egress to Remote Providers, the OAuth callback URL, and network policies for production Meshery.
- Security Hardening - RBAC and least privilege, pod and container security contexts, secret and kubeconfig handling, TLS, supply-chain integrity, Broker exposure risk, and namespace isolation for hardening Meshery in production.
- Authentication, Authorization & Identity - Why to preselect a Remote Provider over the Local Provider, OAuth callback configuration, identity providers, capabilities, and keys/permissions for production Meshery.
- Multi-Cluster & Multi-Cloud Operations - Managed vs. unmanaged cluster connections, one Operator per cluster, kubeconfig and context management, MeshSync deployment modes, and cloud-specific guidance for operating Meshery across many clusters and clouds.
- Monitoring, Observability & Health KPIs - Health endpoints, the key performance indicators of Meshery's health, metrics, distributed tracing, centralized logging, alerting, and synthetic checks for observing Meshery in production.
- Operational Readiness Checklist & Known Caveats - A consolidated, actionable production-readiness checklist across every dimension, the upgrade strategy for Meshery, and the known caveats and limitations to plan around.